- Published on
- Wed May 31, 2023
Part 5 - Persistence and Packaging
Introduction ¶
We have a somewhat bare bones chatservice so far. Our service, exposes endpoints for managing topics and letting users post messages in topics. For a demo, we have been using a makeshift in-memory store that shamelessly provides no durability guarantees. A basic and essential building block in any (web) service is a datastore (for storing, organizing and retrieving data securily and efficiently). In this tutorial we will improve the durability, organization and persistence of data by introducing a database. There are several choice of databases - in-memory (a very basic form of which we have used earlier), object oriented databases, key-value stores, relational databases and more. We will not repeat an indepth comparison of these here and instead defer to others.
Furthermore in this article we will use a relational (SQL) database as our underlying datastore. We will use the popular GORM library (an ORM framework) to simplify access to our our database. There are several relational databases available - both free as well as commercial. We will use Postgres (a very popular, free, lightweight and easy to manage database) for our service. Postgres is also an ideal choice for a primary source-of-truth datastore because of strong durability and consistency guarantees it provides.
Setting up the database ¶
A typical pattern when using a database in a service is:
|---------------| |-----------| |------------| |------|
| Request Proto | <-> | Service | <-> | ORM/SQL | <-> | DB |
|---------------| |-----------| |------------| |------|
- A grpc request is received by the service (we have not shown the rest gateway here).
- The service converts the model proto (eg Topic) contained in the request (eg CreateTopicRequest) into the ORM library.
- The ORM library generates the necessary SQL and executes it on the DB (and returns any results).
Setting up Postgres ¶
We could go the traditional way of installing Postgres (by downloading and installing its binaries for the specific platforms). This is however complicated and brittle. Instead we will start using docker (and docker compose) going forward for a compact developer friendly setup.
Setup docker ¶
Setup Docker Desktop for your platform following the instructions.
Add postgres to docker-compose ¶
Now that docker is setup, we can add different containers to this so we can build out the various components and services OneHub requires.
That’s it. A few key things to note are:
- The docker compose file is an easy way to get started with containers - especially on a single host without needing complicated orchestration engines (hint Kubernetes).
- The main part of a docker compose files are the
servicesections which describe the containers for each of the services that docker compose will be executing as a “single unit in a private network”. This is a great way to package multiple related services needed for an application and bring them all up and down in one step instead of having to manage them one by one individually. The later is not just cumbersome but also error prone (manual dependency management, logging, port checking etc). - For now we have added one service - Postgres - running on port 5432.
- Since the services are running in an isolated context, environment variables can be set to initialize/control the behaviour of the services. These environment variables are read from a specific .env file (below). This file can also be passed as a cli flag or as a parameter but for now we are using the default .env file. Some configuration parameters here are the postgres username, password and database name.
- All data in a container is transient and is lost when the container is shut down. In order to make our database durable, we will store the data outside the container and map it as a volume. This way from within the container, postgres will read/write to its local directory (
/var/lib/postgresql/data) even though all reads/writes are sent to the host’s file system (./.pgdata) - Another great benefit of using docker is that all the ports used by the different services are “internal” to the network that docker creates. Which means the same postgres service (which runs on port 5432) can be run on multiple docker environments without having their ports changed or checked for conflicts. This works because - by default - ports used inside a docker environment are not exposed outside the docker environment. Here we have chosen to expose port 5432 explicitly in the ports section of docker-compose.yml.
That’s it. Go ahead and bring it up:
docker compose up
If all goes well you should see a new postgres database created and initialized with our username, password and db parameters from the .env file. The database is now ready:
onehub-postgres-1 | 2023-07-28 22:52:32.199 UTC [1] LOG: starting PostgreSQL 15.3 (Debian 15.3-1.pgdg120+1) on aarch64-unknown-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit
onehub-postgres-1 | 2023-07-28 22:52:32.204 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
onehub-postgres-1 | 2023-07-28 22:52:32.204 UTC [1] LOG: listening on IPv6 address "::", port 5432
onehub-postgres-1 | 2023-07-28 22:52:32.209 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
onehub-postgres-1 | 2023-07-28 22:52:32.235 UTC [78] LOG: database system was shut down at 2023-07-28 22:52:32 UTC
onehub-postgres-1 | 2023-07-28 22:52:32.253 UTC [1] LOG: database system is ready to accept connections
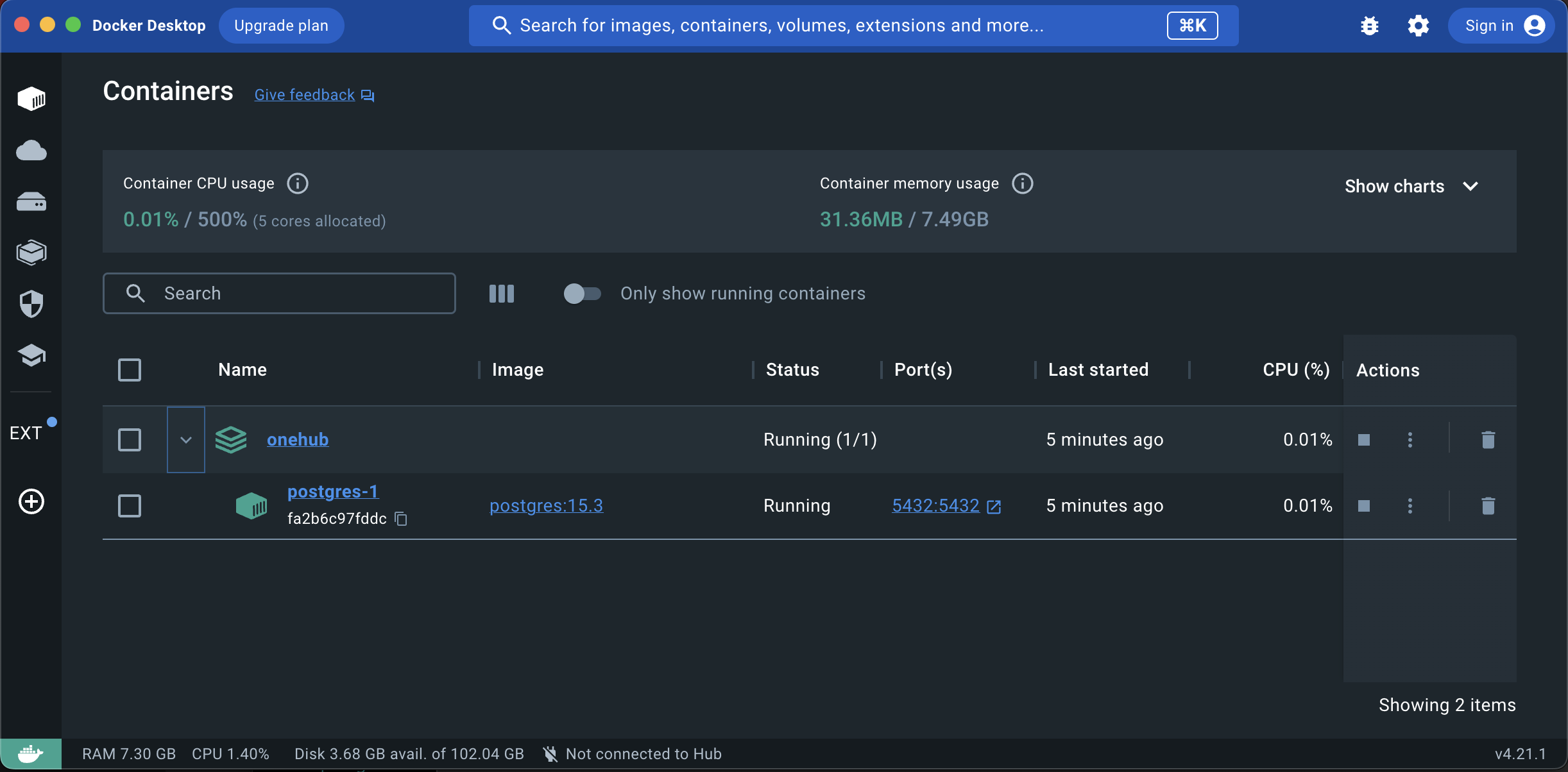
The OneHub docker application should now show up in docker desktop and should look something like this:
(Optional) Setup a DB Admin Interface ¶
If you would like to query or interact with the database (outside code) pgadmin and adminer are great tools. They can be downloaded as native application binaries and installed locally and played. This is a great option if you would like to manage multiple databases (eg across multiple docker environments).
…ALTERNATIVELY…
If it is for this single project and downloading yet another (native app) binary is undesirable, why not just include it as a service within docker itself!! With that added, our docker-compose.yml now looks like:
The accompanying environment variables are in our .env file:
Now you can simply visit the pgadmin web console on your browser. Use the email and password specified in the .env file and off you go! To connect to the postgres instance running in the docker environment, simply create a connection to ‘postgres’ (NOTE - containers local dns names within the docker environment are the service names themselves).
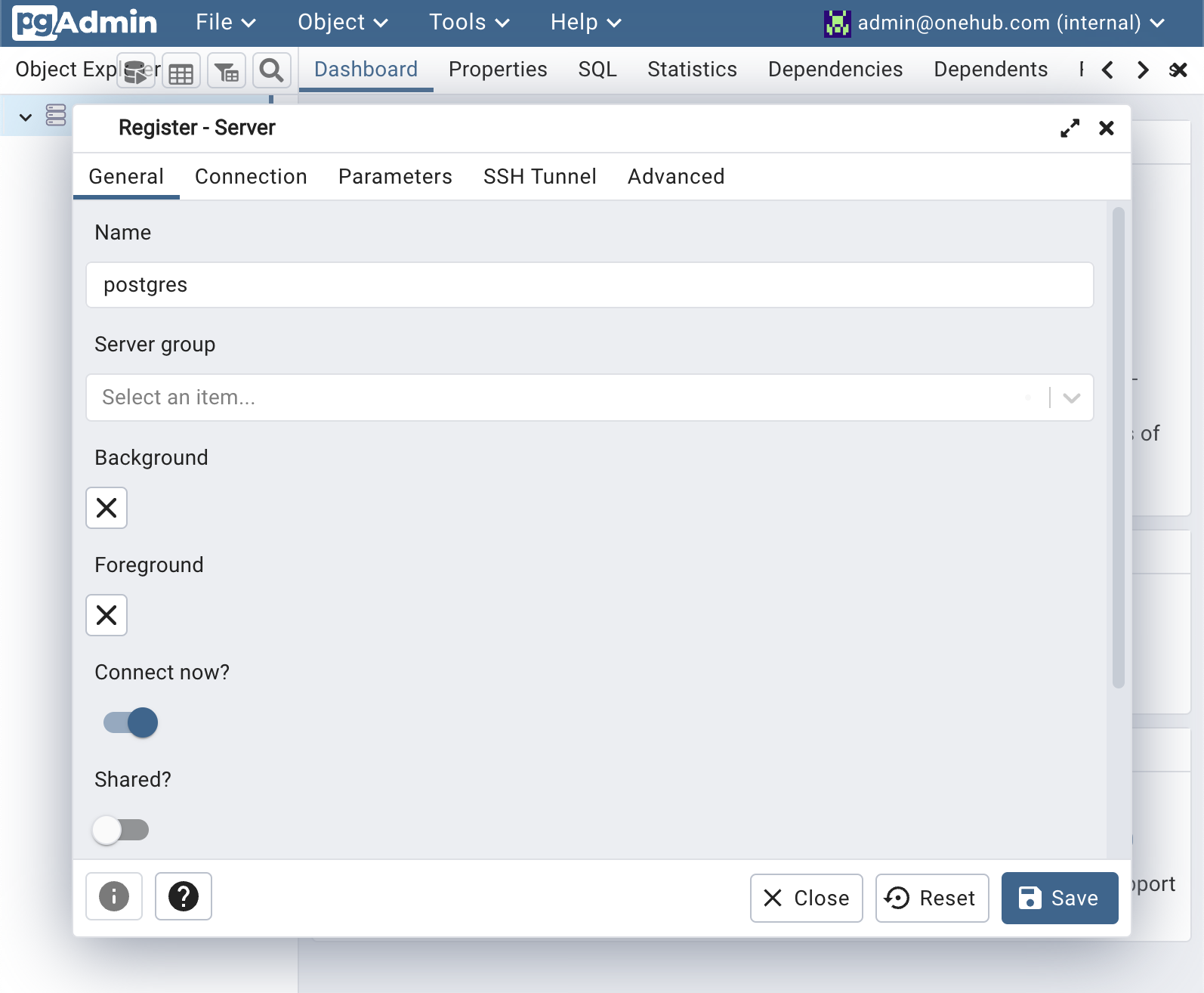
- On the left-side Object Explorer paanel, (Right) Click on
Servers >> Register >> Server...and give a name to your server (“postgres”)
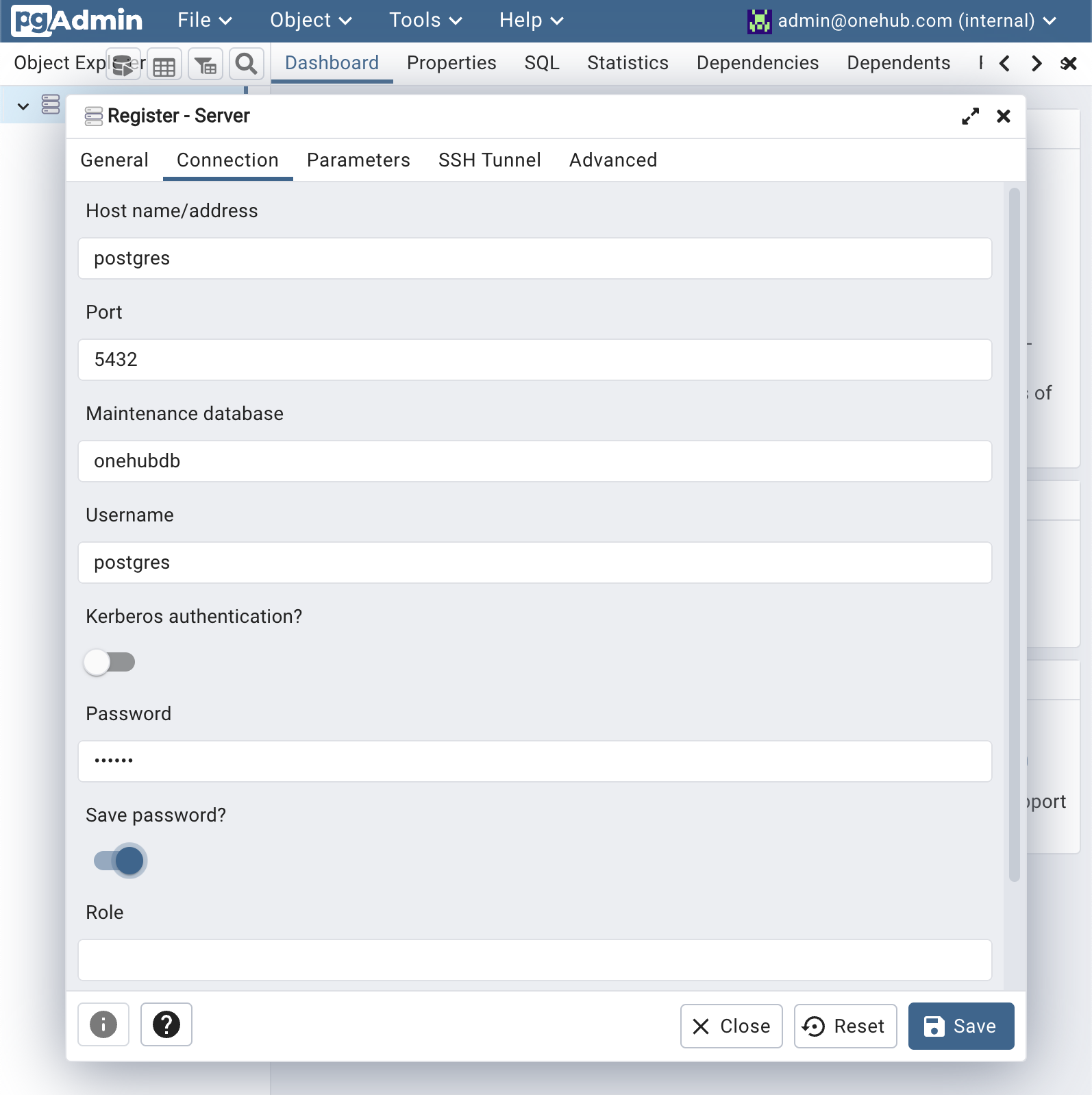
- In the Connection tab use the host name “postgres” and set names of the database, username and password as set in the .env file for the POSTGRES_DB, POSTGRES_USER and POSTGRES_PASSWORD variables respectively.
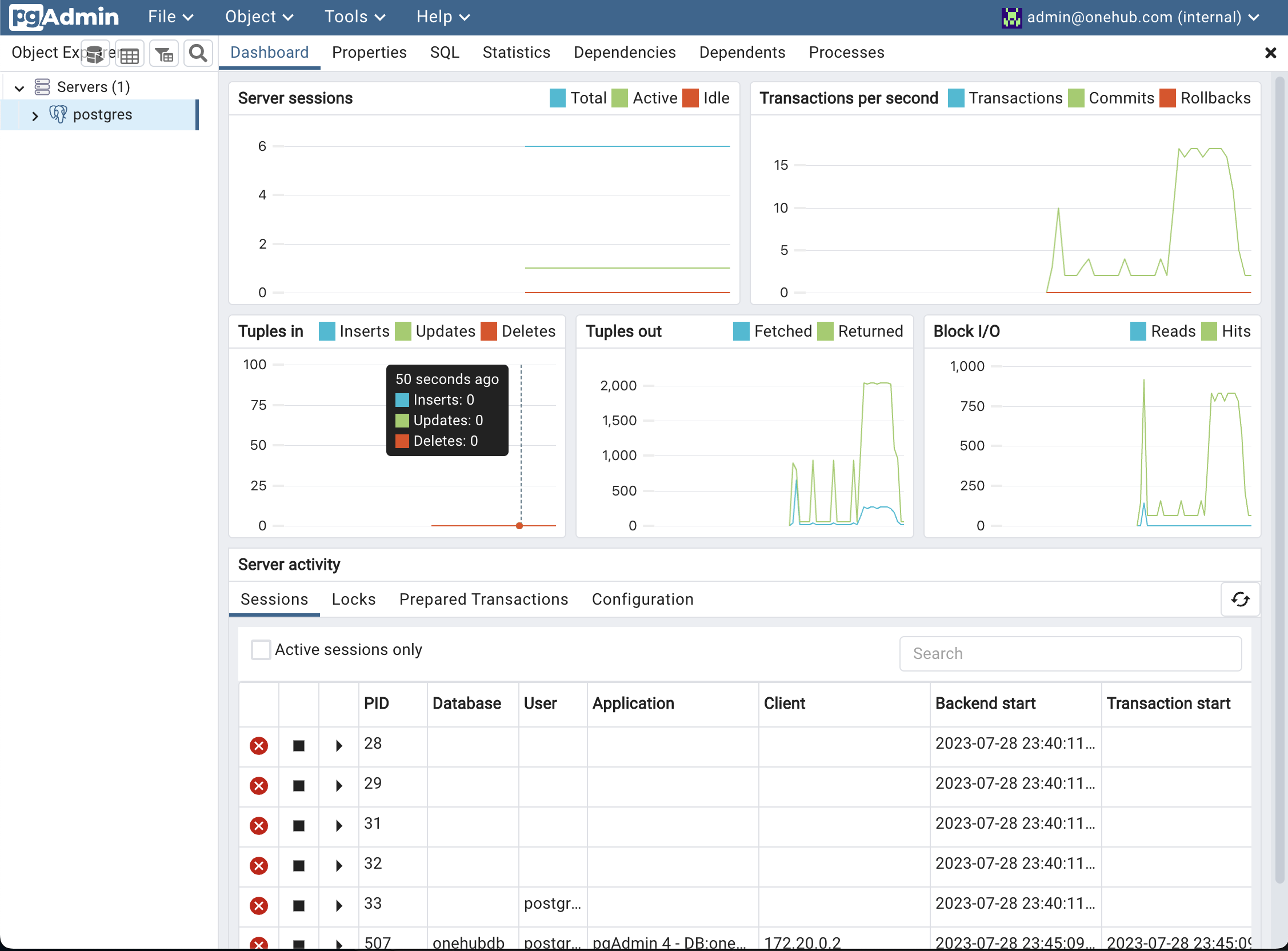
- Click Save and off you go!
Introducing Object Relational Mappers (ORMs) ¶
Before we start updating our service code to access the database, you may be wondering why the grpc service itself is not packaged in our docker-compose.yml file. Without this we would still have to start our service from the command line (or a debugger). This will be detailed in a [future post] (/blog/go-web-services/live-reload-and-debugging).
In a typical database - initialization (after the user, DB setup) would entail creating and running SQL scripts to create tables, checking for new versions and so on. One example of a table creation statement (that can be executed via psql or via pgadmin) is:
1CREATE TABLE topics (
2 id STRING NOT NULL PRIMARY KEY,
3 created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
4 updated_at DATETIME DEFAULT CURRENT_TIMESTAMP,
5 name STRING NOT NULL,
6 users TEXT[],
7);
Similarly an insertion would also have been manual construction of SQL statements, eg:
1INSERT INTO topics
2 ( id, name )
3 VALUES ( "1", "Taylor Swift" );
… followed by a verification of the saved results:
select * from topics ;
This can get pretty tedious (and error prone with vulnerability to sql injection attacks). SQL expertise is highly valuable but seldom feasible - especially being fluent with the different standards, different vendors etc. Even though Postgres does a great job in being as standards compliant as possible - for developers - some ease of use with databases is highly desirable.
Here ORM libraries are indispensible - especially for developers not dealing with SQL on a regular basis (eg yours truly). ORM (Object Relational Mappers) provide an object-like interface onto a relational database. This simplifies access to data in our tables (ie rows) as application level classes (Data Access Objects). Table creations and migrations can also be managed by ORM libraries. Behind the scenes ORM libraries are generating and executing SQL queries on the underlying databases they accessing.
There are downsides to using an ORM:
- ORMs still incur a learning cost for developers during adoption. Interface design choices can play a role in impacting developer productivity.
- ORMs can be thought of as a schema compiler. The underlying sql generated by them may not be straightforward or efficient. This results in ORM access to a database being slower than raw SQL - especially for complex queries. However for complex queries or complex data pattern accesses - other scalability techniques may need to be applied (eg sharding, denormalization etc)
- The queries generated by ORMs may not be clear or straightforward - resulting in increased debugging times on slow or complex queries.
Despite these downsides, ORMs can be put to good use when not overly relied upon. We shall use a popular ORM library - GORM. GORM comes with a great set of examples and documentation and the quick start is a great starting point.
Create DB models ¶
GORM models are our DB models. GORM Models are simple golang structs with struct tags on each member to identify the member’s database type. Our User, Topic and Message models are simply this:
Why are these models needed when we have already defined models in our .proto files? Recall that the models we use need to reflect the domain they are operating in. For example our grpc structs (in .proto files) reflect the models and programming models from the application’s perspective. If/When we build a UI, view-models would reflect the ui/view perspectives (eg a FrontPage view model could be a merge of multiple data models).
Similarly when storing data in a database the models need to convey intent and type information that can be understood and processed by the database. This is why GORM expects data models to have annotations on its (struct) member variables to convey database specific information like column types, index definitions, index column orderings etc. A good example of this in our data model is the SortByTopicAndCreation index (which as the name suggests helps us list topics sorted by their creation timestamp).
Database indexes are one or more (re)organizations of data in a database that speed up retrievals of certain queries (at the cost of increased write times and storage space). We wont go into indexes deeply There are fantastic resources which offer a deep dive into the various internals of database systems in great detail (and would be highly recommended).
The increased writes and storage space must be considered when creating more indexes in a database. We have (in our service) been mindful about creating more indexes and kept these to the bare minimum (to suit certain types of queries). As we scale our services (in future posts) we will revisit how to address these costs by exploring asynchronous and distributed index building techniques.
Data Access Layer Conventions ¶
We now have DB models. We could at this point directly call the GORM apis from our service implementation to read and write data from our (postgres) database. But first a brief detail on the conventions we have decided to choose.
Motivations ¶
Database use can be thought off as being in two extreme spectrums:
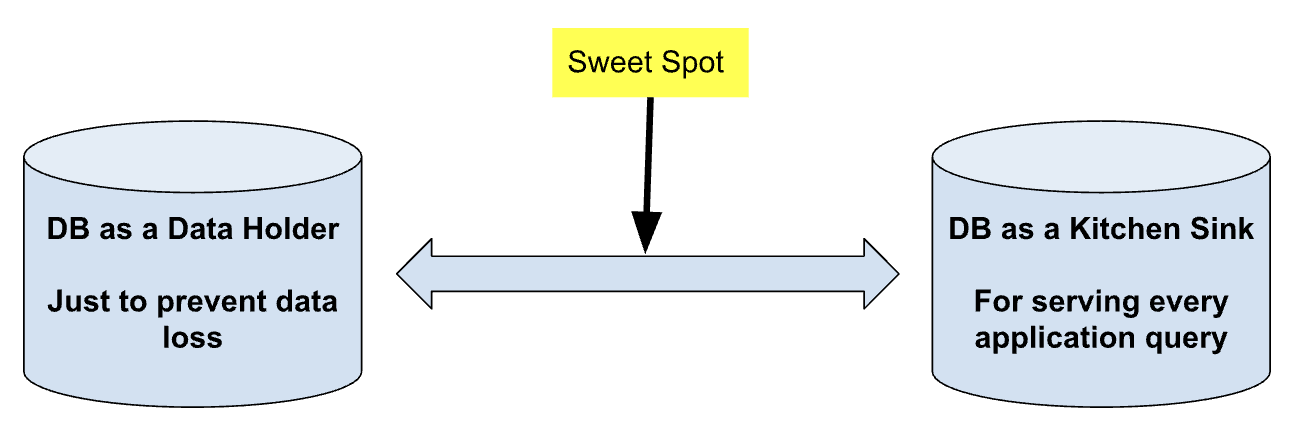
On the one hand a “database” can be treated as a better filesystem with objects written by some key to prevent dataloss. Any structure or consitency guarantees or optimization or indexes are fully the responsibility of the application layer. This gets very complicated, error-prone and hard very fast.
On the other extreme - Use the database engine as the undisputed brains (the kitchen sink) of your application. Every data access for every view in your application is offered (only) by one or very few number of (possibly complex) queries. This view while localizes data access in a single place, also makes the databse a bottleneck and its scalability daunting. In reality vertical scaling (provisioning beefier machines) is the easiest (but an expensive solution - which most vendors will happily recommend) in such cases. Horizontal scaling (getting more machines) is hard as increased data coupling and probabilities of node failures (network partitions) means more complicated and careful tradeoffs between consistency and availability
Our sweetspot is somewhere in between. While ORMs (like GORM) provide an almost 1:1 interface compatibility between SQL and the application needs, being judicious with SQL still remains advantageous and should be based on the (data and operational) needs of the application. For out chat application, some desirable (data) traits are:
- Messages from users must not be lost (Durability)
- Ordering of messages is important (within a topic)
- Few standard query types:
- CRUD on Users, Topics, Messages.
- Messsage ordering by timestamp but limited to either within a topic or by a user (for last N messages)
Given our data “shapes” are simple and given the read usage of our system is much higher especially given read/write amplication (ie 1 message posted is read by many participants on a Topic) - we are choosing to optimize for write consistency, simplicity and read availability (within a reasonable latency).
Now we are ready to will look at the query patterns/conventions.
Unified Database Object ¶
First we will add a simple data access layer which will encapsulate all the calls to the database for each particular model (topic, messages, users). Let us create an overarching “DB” object that representing our postgres DB (in db/db.go):
1type OneHubDB struct {
2 storage *gorm.DB
3}
This tells gorm that we have a database object (possibly with a connection) to the underlying DB. The Topic Store, User Store and Message Store modules all operate on this single DB instance (via GORM) to read/write data from their respective tables (topics, users, messages) Note that this is just one possible convention. We could have instead used three different different DB (gorm.DB) instances - one for each entity type - eg TopicDB, UserDB and MessageDB.
Use custom IDs instead of auto-generated ones ¶
We are choosing to generate our own primary key (IDs) for topics, users and messages instead of depending on the auto-increment (or auto-id) generation by the database engine. This was for the following reasons:
- An auto generated key is localized to the database instance that generates it. This means if/when we add more partitions to our databases (for horizontal scaling) these keys will need to be syncronized and migrating existing keys to avoid duplications at a global level is much harder.
- Auto increment keys offer reduced randomness - making it easy for attackers to “iterate” through all entities.
- Sometimes we may simply want string keys that are custom assignable if they are available (for SEO purposes).
- Lack of attribution to keys (eg a central/global key server can also allow attribution/annotation to keys for analytics purposes)
For this purpose we have added a GenId table that keeps track of all used IDs so we can perform collission detection etc:
1type GenId struct {
2 Class string `gorm:"primaryKey"`
3 Id string `gorm:"primaryKey"`
4 CreatedAt time.Time
5}
Naturally this is not a scalable solution when data volume is large but suffices for our demo and - when needed - we can move this table to a different DB and still preserve the keys/ids. Note that GenId itself is also managed by GORM and uses the combination of Class+Id as its primary key. An example of this is Class=Topic and Id=123.
Random IDs are assigned BY THE APPLICAtion in a simple manner:
1func randid(maxlen int) string {
2 max_id := int64(math.Pow(36, maxlen))
3 randval := rand.Int63() % max_id
4 return strconv.FormatInt(randval, 36)
5}
6
7func (tdb *OneHubDB) NextId(cls string) string {
8 for {
9 gid := GenId{Id: randid(), Class: cls, CreatedAt: time.Now()}
10 err := tdb.storage.Create(gid).Error
11 log.Println("ID Create Error: ", err)
12 if err == nil {
13 return gid.Id
14 }
15 }
16}
- The method
randidgenerates a maxlen sized string of random characters. This is as simple as(2^63) mod maxidwheremaxid = 36 ^ maxlen. - The NextId method is used by the different entity create methods (below) to repeatedly generate random IDs if collissions exist. In case you are worried about or interested in learning about excessive collissions checkout out hash collission probabilities.
Judicious use of indexes ¶
Indexes are very beneficial to speed up certain data retrieval operation at the expense of increased writes and storage. We have limited our use of indexes to a very handful of cases where strong consistency was needed (and could be scaled easily):
- Topics sorted by name (for an alphabetical sorting of topics)
- Messages sorted by Topic and Creation time stamp (for the message list natural ordering)
What is the impact of this on our application? Let us find out…
Topic Creations and Indexes ¶
When a topic is created (or it is updated) an index write would be required. Topic creations/updates are relatively low frequency operations (compared to message postings). So a slightly increased write latency is acceptable. In a more realistic chat application a topic creation is a bit more heavy weight (due to the need to check permissions, apply compliance rules etc). So this latency hit is acceptable. Furthermore this index would only be needed when “searching” for topics and even an asynchronous index update would have sufficed.
Message related indexes ¶
To consider the usefulness of indexes related to Messages let us look at some usage numbers. This is a very simple application so these scalability issues most likely wont be a concern (so feel free to skip this section). If your goals are a bit more lofty, looking at Slack’s usage numbers we can estimate/project some usage numbers for our own demo to make it interesting:
- Number of daily active topics: 100
- Number active users per topic: 10
- Message sent by an active user in a topic - every 5 minutes (assume time to type, to read others messages, research, think etc)
Thus, number of messages created each day
= 100 * 10 * (1400 minutes in a day / 5 minutes)
= 280k messages per day
~ 3 messages per second
In the context of these numbers if we were to create a message every 3 seconds, even with an extra index (or three) we can handle this load comfortably in a typical database that can handle 10k iops (which is rather modest).
It is easy to wonder if this scales as the number of topics or active users per topic or the creation frenzy increased. Let us consider a more intense setup (in a larger or busier organization). Instead of the numbers above if we had 10k topics and 100 active users with a message every minute (instead of 5 minutes), our write QPS would be:
WriteQPS
= 10000 * 100 * 1400 / 1
= 1.4B messages per day
~ 14k messages per second
That is quite a considerable blow up. We can solve this in a couple of ways:
-
Accept a higher latency on writes - ie instead of requiring a write happen in a few milliseconds - accept an SLO of say 500ms.
-
Update indexes asynchonously - this doesnt get us that much further as the number of writes in a system has not changed - only the when has changed.
-
Shard our data
Let us look at sharding! Our write QPS is in aggregate. On a per-topic level it is quite low (14k / 10000 = 1.4 qps). However user behaviour (for our application) is that such activities on a topic are fairly isolated. We only want our messages to be consistent and ordered within a topic - not globally. We now have the opportunity to dynamically scale our databases (or the Messages tables) to be partitioned by topic IDs. Infact we could build a layer (a control plane) that dynamically spins up database shards and moves topics around reacting to load as and when needed. We will not go that extreme here (but this series is tending towards just that especially in the context of SaaS applications).
This deep dive was understandably not mandatory right now! However by understanding our data and user experience needs we could make careful tradeoffs. Going forward such mini dives will benefit us immensely as we want to quickly evaluate tradeoffs (when building/adding new features).
Store specific implementations ¶
Now that we have our basic DB and common methods, we can go to each of the entity methods’ implementations. For each our entity methods we will create the basic CRUD methods:
- Create
- Update
- Get
- Delete
- List/Search
-
The Create and Update methods are combined into a single “Save” method to do the following:
- If an ID is not provided then treat as a create
- If an ID is provided treat it as an update-or-insert (upsert) operation by using the NextId method if necessary
-
Since we have a base model, Create and Update will set CreatedAt and UpdatedAt fields respectively.
-
The delete method is straight forward. Only key thing here is instead of leveraging GORM’s cascading deletes capabilities we also delete the related entities in a separate call. We will not worry about consistency issues resulting from this (eg errors in subsequent delete methods).
-
For the Get method - we will fetch using a standard Gorm get-query-pattern based on a common id column we use for all models. If an entity does not exist then we return a nil.
Users DB ¶
Our user entity methods are pretty straightforward using the above conventions The Delete method additionally also deletes all Messages for/by the user first before deleting the user itself. This ordering is to ensure that if deletion of topics fails then the user deletion wont proceed giving the caller to retry.
Topics DB ¶
Our topic entity methods are also pretty straightforward using the above conventions The Delete method additionally also deletes all messages in the topic first before deleting the user itself. This ordering is to ensure that if deletion of topics fails then the user deletion wont proceed giving the caller a chance to retry.
Messages DB ¶
The Messages entity methods are slightly more involved. Unlike the other two, Messages entity methods also include Searching by Topic and Searching by User (for ease).
This is done in the GetMessages method that provides paginated (and ordered) retrieval of messages for a topic or by a user.
Write converters to/from Service/DB models ¶
We are almost there. Our database is ready to read/write data. It just needs to be invoked by the service. Going back to our original plan:
|---------------| |-----------| |--------| |------|
| Request Proto | <-> | Service | <-> | GORM | <-> | DB |
|---------------| |-----------| |--------| |------|
We have our service models (generated by protobuf tools) and we have our DB models that GORM understands. We will now add converters to convert between the two. Converters for Entity X will follow these conventions:
- A method XToProto of type
func(input *datastore.X) (out *protos.X) - A method XFromProto of type
func(input *protos.X) (out *datastore.X)
With that our converters are quite simply (and boringly):
Hook up the converters in the Service Definitions ¶
Our last step is to invoke the converters above in the service implementation. An example is the TopicService below that shows the converters in action:
The methods are pretty straight forward.
CreateTopic
- During creation we allow custom IDs to be passed in. If an entity with the ID exists the request is rejected. If an ID is not passed in a random one is assigned.
- Creator and Name parameters are required fields.
- The topic is converted to a “DBTopic” model and saved by calling the SaveTopic method.
UpdateTopic
All our Update<Entity> methods follow a similar pattern:
- Fetch the existing entity (by ID) from the DB.
- Update the entity fields based on fields marked in the update_mask (so patches are allowed)
- Update with any extra entity specific operations (eg AddUsers, RemoveUsers etc) - these are just for convinience so the caller would not have to provide an entire “final” users list each time.
- Convert the updated proto to a “DB Model”
- Call SaveTopic on the DB. SaveTopic uses the “version” field in our DB to perform an optimistically concurrent write. This ensures tha if by the time the model is loaded and it is being written, a write by another request/thread will not be overwritten.
The Delete, List and Get methods are fairly straightward. The UserService and MessageService also are implemened in a very similar way with minor differences to suit specific requirements.
Testing it all out ¶
We have a database up and running (go ahead and start it with docker compose up). We have converters to/from service and database models. We have implemented up our service code to access the database. We just need to connect to this (running) database and pass a connection object to our services in our runner binary (cmd/server.go):
- Add an extra flag to accept a path to the DB. This can be used to change the DB path if needed.
1var (
2 addr = flag.String("addr", ":9000", "Address to start the onehub grpc server on.")
3 gw_addr = flag.String("gw_addr", ":8080", "Address to start the grpc gateway server on.")
4
5 db_endpoint = flag.String("db_endpoint", "", fmt.Sprintf("Endpoint of DB where all topics/messages state are persisted. Default value: ONEHUB_DB_ENDPOINT environment variable or %s", DEFAULT_DB_ENDPOINT))
6)
- Create
*gorm.DBinstance from the db_endpoint value
We have already created a little utility method for opening a (gorm compatible) SQL DB given an address:
Now let us create the method OpenOHDB - which is a simple wrapper that also checks for a db_endpoint value from an environment variables (if it is not provided) and subsequently opens a gorm.DB instance needed for a OneHubDB instance:
1func OpenOHDB() *ds.OneHubDB {
2 if *db_endpoint == "" {
3 *db_endpoint = cmdutils.GetEnvOrDefault("ONEHUB_DB_ENDPOINT", DEFAULT_DB_ENDPOINT)
4 }
5 db, err := cmdutils.OpenDB(*db_endpoint)
6 if err != nil {
7 log.Fatal(err)
8 panic(err)
9 }
10 return ds.NewOneHubDB(db)
11}
With the above two we need a simple change to our main method:
1func main() {
2 flag.Parse()
3 ohdb := OpenOHDB()
4 go startGRPCServer(*addr, ohdb)
5 startGatewayServer(*gw_addr, *addr)
6}
Now we shall also pass the ohdb instance to the GRPC service creation methods. And we are ready to test our durability! Remember we setup auth in a previous part so we need to pass login credentials - albeit fake ones (where password = login + "123")
Create a Topic ¶
curl localhost:8080/v1/topics -u auser:auser123 | json_pp
1{
2 "nextPageKey" : "",
3 "topics" : []
4}
That’s right. We do not have any topics yet so let us create some.
1curl -X POST localhost:8080/v1/topics \
2 -u auser:auser123 \
3 -H 'Content-Type: application/json' \
4 -d '{"topic": {"name": "First Topic"}}' | json_pp
yielding:
1{
2 "topic" : {
3 "createdAt" : "1970-01-01T00:00:00Z",
4 "creatorId" : "auser",
5 "id" : "q43u",
6 "name" : "First Topic",
7 "updatedAt" : "2023-08-04T08:14:56.413050Z",
8 "users" : {}
9 }
10}
Let us create a couple more:
curl -X POST localhost:8080/v1/topics \
-u auser:auser123 \
-H 'Content-Type: application/json' \
-d '{"topic": {"name": "First Topic", "id": "1"}}' | json_pp
curl -X POST localhost:8080/v1/topics \
-u auser:auser123 \
-H 'Content-Type: application/json' \
-d '{"topic": {"name": "Second Topic", "id": "2"}}' | json_pp
curl -X POST localhost:8080/v1/topics \
-u auser:auser123 \
-H 'Content-Type: application/json' \
-d '{"topic": {"name": "Third Topic", "id": "3"}}' | json_pp
with a list query returning:
1{
2 "nextPageKey" : "",
3 "topics" : [
4 {
5 "createdAt" : "1970-01-01T00:00:00Z",
6 "creatorId" : "auser",
7 "id" : "q43u",
8 "name" : "First Topic",
9 "updatedAt" : "2023-08-04T08:14:56.413050Z",
10 "users" : {}
11 },
12 {
13 "createdAt" : "1970-01-01T00:00:00Z",
14 "creatorId" : "auser",
15 "id" : "dejc",
16 "name" : "Second Topic",
17 "updatedAt" : "2023-08-05T06:52:33.923076Z",
18 "users" : {}
19 },
20 {
21 "createdAt" : "1970-01-01T00:00:00Z",
22 "creatorId" : "auser",
23 "id" : "zuoz",
24 "name" : "Third Topic",
25 "updatedAt" : "2023-08-05T06:52:35.100552Z",
26 "users" : {}
27 }
28 ]
29}
Get Topic by ID ¶
We can do a listing as in the previous section. We can also obtain individual topics:
curl localhost:8080/v1/topics/q43u -u auser:auser123 | json_pp
1{
2 "topic" : {
3 "createdAt" : "1970-01-01T00:00:00Z",
4 "creatorId" : "auser",
5 "id" : "q43u",
6 "name" : "First Topic",
7 "updatedAt" : "2023-08-04T08:14:56.413050Z",
8 "users" : {}
9 }
10}
Send and List messages on a topic ¶
Let us send a few messages on the “First Topic” (id = “q43u”):
curl -X POST localhost:8080/v1/topics/q43u/messages -u 'auser:auser123' -H 'Content-Type: application/json' -d '{"message": {"content_text": "Message 1"}}'
curl -X POST localhost:8080/v1/topics/q43u/messages -u 'auser:auser123' -H 'Content-Type: application/json' -d '{"message": {"content_text": "Message 2"}}'
curl -X POST localhost:8080/v1/topics/q43u/messages -u 'auser:auser123' -H 'Content-Type: application/json' -d '{"message": {"content_text": "Message 3"}}'
Now to list them:
curl localhost:8080/v1/topics/q43u/messages -u 'auser:auser123' | json_pp
{
"messages" : [
{
"contentData" : null,
"contentText" : "Message 1",
"contentType" : "",
"createdAt" : "0001-01-01T00:00:00Z",
"id" : "hlso",
"topicId" : "q43u",
"updatedAt" : "2023-08-07T05:00:36.547072Z",
"userId" : "auser"
},
{
"contentData" : null,
"contentText" : "Message 2",
"contentType" : "",
"createdAt" : "0001-01-01T00:00:00Z",
"id" : "t3lr",
"topicId" : "q43u",
"updatedAt" : "2023-08-07T05:00:39.504294Z",
"userId" : "auser"
},
{
"contentData" : null,
"contentText" : "Message 3",
"contentType" : "",
"createdAt" : "0001-01-01T00:00:00Z",
"id" : "8ohi",
"topicId" : "q43u",
"updatedAt" : "2023-08-07T05:00:42.598521Z",
"userId" : "auser"
}
],
"nextPageKey" : ""
}
Conclusion ¶
Who would have thought setting up and using a database would have been such a meaty topic. We covered a lot of ground here that will both give us a good “functioning” service as well as with a foundation when implementing new ideas in the future:
- We chose a relational database - Postgres - for its strong modelling capabilities, consistency guarantees, performance and versatility.
- We also chose an ORM library (GORM) to improve our velocity and portability if we need to switch to another relational datastore.
- We wrote data models that GORM could use to read/write from the database.
- We eased the setup by hosting both postgres and its admin ui (Pgadmin) in a docker-compose file.
- We decided to use GORM carefully and judiciously to balance velocity with minimal reliance on complex queries.
- We discussed some conventions that will help us along in our application design and extensions.
- We also addressed a way to assess, analyse and address scalability challenges as they might arise and use that to guide our tradeoff decisions (eg type and number of indexes, etc).
- We wrote converters methods to convert between service and data models.
- We finally used the converters in our service to offer a “real” persistent implementation of a chat service where messages can be posted and read.
Now that we have a “minimum usable app” and there are a lot of useful features to add to our service and make it more and more realistic (and hopefully production ready). Take a breather and see you soon in continuing the exciting adventure! In the next post we will look at also including our main binary (with grpc service and rest gateways) in the docker compose environment without sacrificing hot reloading and debugging.