- Published on
- Mon Jun 24, 2024
Part 9 - Full Text Search
Introduction ¶
In this post (Part 9) of our series on building web services in Go, we will show how to enable search capabilities on our topics and messages. Full text search would allow users to search topics and messages by different facts (eg by titles, descriptions, message contents, users, and other tags).
Current Architecture ¶
Postgres is a highly customizable database engine which rapidly onboards new indexing and querying capabilities via extensions. It is no surprise that several such extensions exists (eg tsvector, pgvector) for powering full text searches. Our current architecture (without showing the frontend services) has Postgres powering both source-of-truth as well as querying capabilities:

Here our main entity related CRUD requests are handled (via services) by Postgres. Our retrieval/search/listing queries are also handled by Postgres. Currently our database has a small number of indexes (Topics sorted by timestamp, messages sorted by topicid+timestamp, messages by ID, topics by ID). When an entity is created (or updated) its associated indexes are also updated. The storage requirements also increase (in our main database) to accomodate each index. The search queries are uptodate and consistent on each write. But as the number (and/or complexity) of indexes grows (eg indexing by tags, vector indexes on title/description etc) writes will become expensive - limiting scale.
Another factor is horizontal scaling. Though databases can be sharded/partitioned horizontally (eg based on Entities’ ID/Primary Keys) indexing introduces a few challenges. Recall that indexes are “inverse” relationships. While we can partition an entity based on its ID, the index entries that an entity maps to may fall on different shards (eg different physical hosts). This means a write to a single record may need transactional updates to multiple index shards. This may be very expensive as locking will be needed. Even worse in such distributed systems node failures may mean writes can be very flaky and unreliable.
Goals ¶
So we want search. Before diving into the final architecture, let us highlight what we want from our search system (both functionally and operationally). This will influence our choice of design, architecture and technologies.
- Individual entity updates must be fast, durable and consistent (eg Topic creations, Topic updates, message sends/deletions/listings must succeed quickly without data-loss).
- Searching messages/topics (by different fields) must be fast but we want to vary how quickly an action in (1) is reflected in a respective search result. For example if user A creates a topic, T1, then it may not be immediately visible for user B’s search topics query. But user B must eventually see T1.
- It must be (reasonably) easy to update/manage/configure search indexes and even re-index them with idempotency guarantees.
- System must scale horizontally so we can grow based on different fault domains and it must be easy to spin up.
As we scale our system we may be ok to tolerate delays between an entity update and when it is visible in a search query. This is known as eventual consistency.
Time for a small pause here. Sharding, Replication, Fault tolerance (and more) are key concepts in distributed systems - Martin Klepmann’s classic is a MUST READ book for any distributed systems enthusiast. We will not go into details all at once and instead address these concepts as we encounter them.
Proposal ¶
Given our requirements we can start with one architecture that allows indexes that can be built incrementally and asynchronously:

The key parts of this flow are:
- Users create/update/delete entities
- The respective services write entities and update the Source of Truth DB (postgres)
- The datastore - through its change data capture (CDC) interface - sends entity change events to the Sync service (
DBSync). - DBSync (our Sync service) updates the index entries by writing changed records to another datastore that is optimized for querying.
A few things to note:
- We are seperating our source of truth DB from the search store so that we can use different systems optimized for different needs. SoT for consistent CRUD operations, Search store for fast, flexible and scalable searches.
- We are using a single “entrypoint” into indexing - DBSync - which ensures that an entity that is updated is reflected correctly in all future searches.
- Note that (2) and (3) both are not needed. These both should exist only if the sync operation on a change is idempotent - something the DBSync should guarantee. We will see how this is ensured.
- A change data capture (CDC) system may not be available universally in which case Step 2 above needs to be resilient to write errors. But CDC is available in most modern databases and Postgres is no exception.
- DBSync will ensure that manual/adhoc syncs can also be done for entries when needed. Though this should rarely be needed and is more of a test/debug mechanism.
- The access to the search store is wrapped by Search service (on the read path) and by DBSync (on the update path). This ensures that we can change the datastores without affecting the behaviour of our application. Another advantage of this is that we can shard/horizontally scale the Search service and DBSync independantly of the underlying store.
- Both the Search service and DBSync are application specific and do not leak details of the underlying search store. Eg they will translate application specific queries of the form
getTopicsByTags(...)into queries in the underlying store eg -typesence.collections('topics').search(....)
There are several choices for the search store:
- Elasticsearch -
- Postgres - With full text search extensions like tsvector, pgvector
- Typesense
- and others.
In our post we will use Typesense as our search store. Why? Why not?
Setup Typesense ¶
First let us add another dependency in our db-docker-compose.yml to include typesense:
typesense:
networks:
- onehubnetwork
image: typesense/typesense:26.0-arm64
restart: on-failure
ports:
- 8108:8108
volumes:
- ./.data/typesensedata:/data
command: '--data-dir /data --api-key=my_api_key --enable-cors'
With this we have Typesense running on port 8108 (and exposed on the same port). Typesense needs an API Key for validating its sclients so we have created one (my_api_key). We can pass these as TYPESENSE_HOST and TYPESENSE_API_KEY environment variables for any other container that needs discover and access it. To see the entities created in the database we are using a simple dashboard web-app - typesense-dashboard - also in db-docker-compose.yml:
typesense-dashboard:
image: typesense-dashboard
volumes:
- ./configs/tsdash.config:/srv/config.json
ports:
- 8180:80
Before doing this however ensure you have built the typesense-dashboard docker image built:
cd /tmp
git clone https://github.com/bfritscher/typesense-dashboard.git
cd typesense-dashboard
docker build -t typesense-dashboard .
Going to the typesense-dashboard page should greet you with:
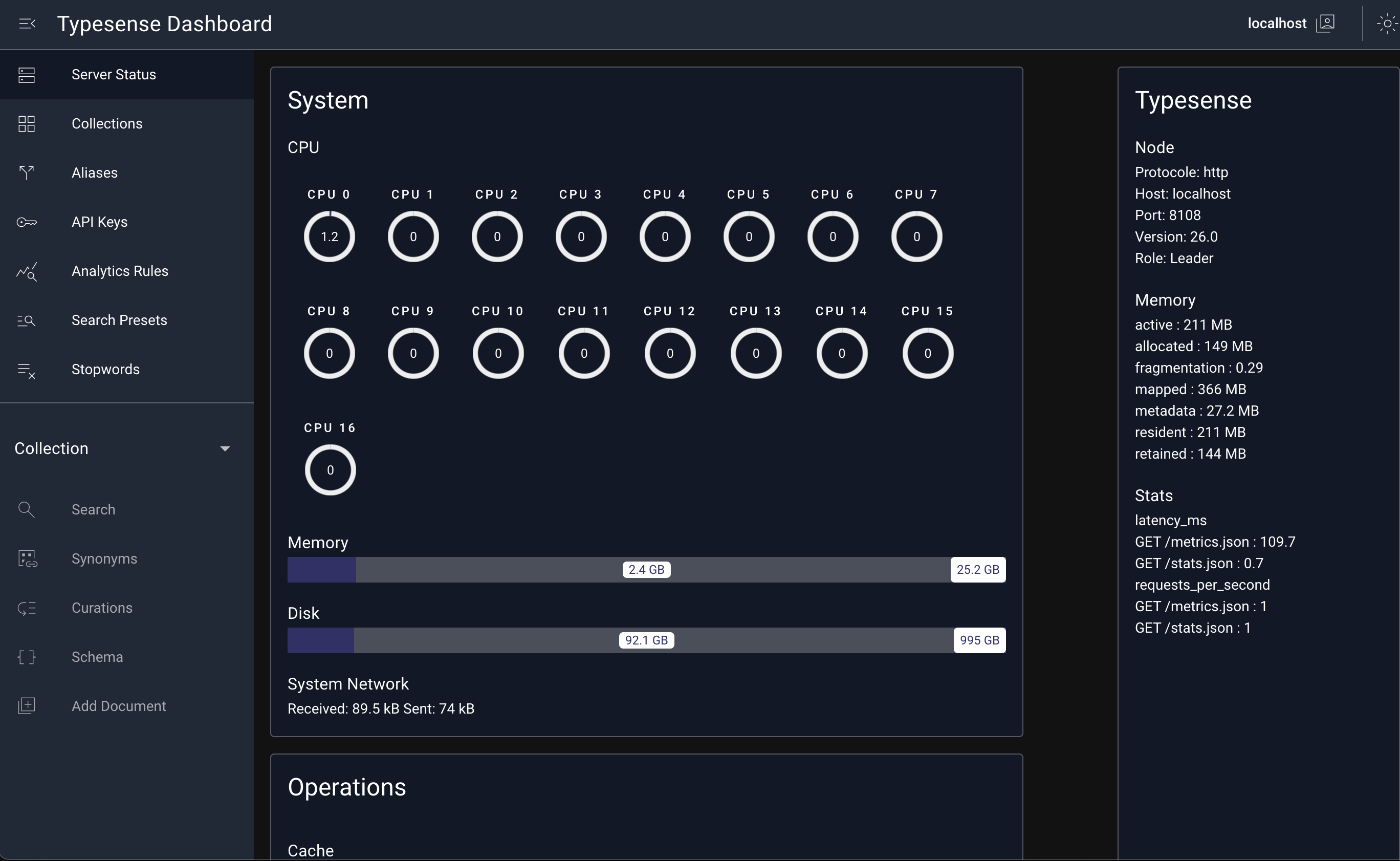
As you can see right now you do not have any entities created (as a result of the DB sync). So let us go ahead and do that now.
Setup Typesense libraries ¶
You can even try out some sample calls by using one of the many available client libraries.
Also install the python client library which will come in handy as we query Typesense locally:
pip install typesense
Setup the Sync Service ¶
There are two parts to our database Sync Service.
- The common platform level component that listens to change capture events from postgresql and exposes them as hooks to be implemenented. This has been extracted out into a go library dbsync.
- Onehub specific sync logic that implements the interfaces exposed by the dbysnc library (eg changes from our postgres DB) to reflect the changes in ourour Typesense index store.
In this post we will not talk much about (1). The Dbsync library is still WIP and as such not fully documented. We will touch upon the interfaces it exposes and those are used to implement (2) above.
The onehub implementation of DBSync is in cmd/dbsync/main.go. Let us go through this step by step:
Setup the TypeSense schemas ¶
Entities in Typesense are stored as deep documents. However for better indexing, it is beneficial to have schemas (type definitions for records) for the entities we are interested in - users, topics and messages.
For example to setup the user schema we do (in the main method of cmd/dbsync/main.go):
p := NewPG2TS()
p.tsclient.EnsureSchema("public.users", []gut.StringMap{
{"name": "id", "type": "string"},
{"name": "version", "type": "int64"},
{"name": "created_at", "type": "int64"},
{"name": "updated_at", "type": "int64"},
{"name": "name", "type": "string"},
{"name": "avatar", "type": "string", "optional": true},
{"name": "profile_data", "type": "object", "optional": true},
})
[Line 1]: We first create PG2TS struct instance (this type keeps track of various objects needed/used during the db sync process)
[Line 2-10]: EnsureSchema on the typesense client (p.tsclient) sets up record and field definitions for the user entity type in TS.
We do the same for topics and messages (see the main method). Once these are setup, the sync is started with p.Start().
Implement DBSync Interface ¶
Let us look at part of the interface exposed by the dbsync library. Specifically the PGMSGHandler type:
type PGMSGHandler struct {
LastBegin int
LastCommit int
DB *PGDB
HandleBeginMessage func(m *PGMSGHandler, idx int, msg *pglogrepl.BeginMessage) error
HandleCommitMessage func(m *PGMSGHandler, idx int, msg *pglogrepl.CommitMessage) error
HandleRelationMessage func(m *PGMSGHandler, idx int, msg *pglogrepl.RelationMessage, tableInfo *PGTableInfo) error
HandleUpdateMessage func(m *PGMSGHandler, idx int, msg *pglogrepl.UpdateMessage, reln *pglogrepl.RelationMessage) error
HandleDeleteMessage func(m *PGMSGHandler, idx int, msg *pglogrepl.DeleteMessage, reln *pglogrepl.RelationMessage) error
HandleInsertMessage func(m *PGMSGHandler, idx int, msg *pglogrepl.InsertMessage, reln *pglogrepl.RelationMessage) error
relnCache map[uint32]*pglogrepl.RelationMessage
}
The interesting bits are the Handle* methods (which are wrappers over another lower level CDC library - pglogrepl). These methods handle various changes coming from the underlying (postgres) DB. Our dbsync service simply implements the HandleUpdateMessage, HandleInserMessage and HandleDeleteMessage methods (in the NewPG2TS constructor method):
HandleInsertMessage: ¶
HandleInsertMessage: func(m *dbsync.PGMSGHandler, idx int, msg *pglogrepl.InsertMessage, reln *pglogrepl.RelationMessage) error {
pkey, outmap, errors := dbsync.MessageToMap(out.pgdb, msg.Tuple, reln)
if errors != nil {
log.Println("Error converting to map: ", pkey, errors)
}
// Get the created and updated timestampes from the message
if _, ok := outmap["created_at"]; ok {
outmap["created_at"] = outmap["created_at"].(time.Time).Unix()
}
if _, ok := outmap["updated_at"]; ok {
outmap["updated_at"] = outmap["updated_at"].(time.Time).Unix()
}
// Get the table/relation entity being inserted into
tableinfo := out.pgdb.GetTableInfo(reln.RelationID)
doctype := fmt.Sprintf("%s.%s", reln.Namespace, reln.RelationName)
docid := tableinfo.GetRecordID(msg.Tuple, reln)
if _, ok := out.upserts[doctype]; !ok {
out.upserts[doctype] = make(map[string]gut.StringMap)
}
if _, ok := out.deletions[doctype]; !ok {
out.deletions[doctype] = make(map[string]bool)
}
// If the docuemnt was already marked for "deletion" then undo this
// and mark it as inserted "compact" and batch changes on a per document ID
// basis instead of making changes to the typesense DB on every update
delete(out.deletions[doctype], docid)
out.upserts[doctype][docid] = outmap
return nil
},
HandleDeleteMessage: ¶
HandleDeleteMessage: func(m *dbsync.PGMSGHandler, idx int, msg *pglogrepl.DeleteMessage, reln *pglogrepl.RelationMessage) error {
// Instead of individual deletes we will batch them by collections
tableinfo := out.pgdb.GetTableInfo(reln.RelationID)
doctype := fmt.Sprintf("%s.%s", reln.Namespace, reln.RelationName)
docid := tableinfo.GetRecordID(msg.OldTuple, reln)
if _, ok := out.upserts[doctype]; !ok {
out.upserts[doctype] = make(map[string]gut.StringMap)
}
if _, ok := out.deletions[doctype]; !ok {
out.deletions[doctype] = make(map[string]bool)
}
delete(out.upserts[doctype], docid)
out.deletions[doctype][docid] = true
return nil
},
Enable Postgres for Logical Replication ¶
Set wal_level ¶
Our postgres DB’s data folder (./.data/pgdata) contains the postgres config file (postgresql.conf). Ensure that the wal_level parameter is set to “logical”.
Create a publication ¶
Postgres offers Publications as a way to allow selected tables to participate in change captures as a group (pun unintended). In our case we want to capture all changes on the Topics, Messages and Users table so we can replicate this onto our search index:
CREATE PUBLICATION <PUBLICATION_NAME> FOR TABLE users, messages, topics ;
By default the name of the publication is dbsync_mypub. This publication will be listened to by DBSync (next) to update the search index continuously. This can also be configure with the DBSYNC_PUBNAME parameter in your .env file.
Sync service (DBSync) ¶
There are several tools one could use for CDC based index building. One such tool is Debezium. However we will NOT be using it. For fun’s sake and we built a replication mechanism based on the more powerful DBLog (by Netflix). This has also been enabled in our docker-compose file as the dbsync service.
We will not go over this service in this post and instead go into a thorough deeper dive in a future post. Briefly DBSync works as follows:
- Postgres has several replication schemes. DBSync takes advantage of logical replication but can be made to work with any scheme (including streaming replication).
- The publication created in the previous step will be subscribed by DBSync.
- DBSync in turn translates the log events (entity created, updated, deleted) into respective Typesense api calls (delete entity and upsert entity). These can be found in the dbsync binary that is started as a long running process in our docker environment.
Test the Index Store ¶
Typesense can be queried directly via REST api calls or other client libraries. However it is not a safe or scalable practise to offer direct access to a search index store from our frontend. You can still go ahead and try it locally in python.
Assuming you have already brought up the dbsync service (with docker compose up), start python for the following:
Start python/ipython: ¶
import typesense
tsclient = ts.Client({"api_key": "xyz", # From above
"nodes": [{
"host": "localhost",
"port": 8108,
"protocol": "http"
}]
})
Query the collection schemas ¶
DBSync had created 3 Typesense collections for us - “public.topics”, “public.users” and “public.messages”.
For example the “public.topics” collection’s schema would look like:
In [4]: tsclient.collections["public.topics"].retrieve()
Out[4]:
{
'created_at': 1695075731,
'default_sorting_field': '',
'enable_nested_fields': True,
'fields': [
{'facet': False, 'index': True, 'infix': False, 'locale': '', 'name': 'version', 'optional': False, 'sort': True, 'type': 'int64'},
{'facet': False, 'index': True, 'infix': False, 'locale': '', 'name': 'created_at', 'optional': False, 'sort': True, 'type': 'int64'},
{'facet': False, 'index': True, 'infix': False, 'locale': '', 'name': 'updated_at', 'optional': False, 'sort': True, 'type': 'int64'},
{'facet': False, 'index': True, 'infix': False, 'locale': '', 'name': 'users', 'optional': True, 'sort': False, 'type': 'string[]'}
],
'name': 'public.topics',
'num_documents': 0,
'symbols_to_index': [],
'token_separators': []
}
Retrieve Entities ¶
With DBSync running we can fetch documentsfrom the different collections, eg:
Get a user by ID:
In [23]: client.collections["public.users"].documents["ltuser1"].retrieve()
Out[23]:
{
'created_at': 0,
'id': 'ltuser1',
'name': 'Forceful Coyote',
'updated_at': 1695009058,
'version': 0
}
Create a topic:
In [34]: client.collections["public.topics"].documents.create({"id": "testtopic", "name": "My Topic", "updated_at: ": int(time.time()), "created_at": int(time.time()), "version": 0})
Out[34]:
{
'created_at': 1695160379,
'id': 'testtopic',
'name': 'My Topic',
'updated_at': 1695160379,
'version': 0
}
Delete a topic by ID:
In [22]: tsclient.collections["public.topics"].documents["lt100"].delete()
Out[22]:
{
'id': 'lt100',
'created_at': 0,
'creator_id': 'ltuser81',
'name': 'What do you think of Serena Williams?',
'updated_at': 1695159795,
'version': 0
}
Fetch 3 messages:
In [7]: tsclient.collections["public.messages"].documents.search({"q": "*", "order_by": "id", "per_page": 3})
Out[7]:
{'found': 188378,
'hits': [{
'document': {
'content_text': " That's really crazy. I saw that they had a carnival ride and a pink themed splashed party room.",
'content_type': 'text/plain',
'created_at': 1694449315,
'id': 'zanhcyvy',
'topic_id': 'lt35',
'updated_at': 1694449315,
'user_id': 'ltuser49',
'version': 0
},
},
{
'document': {
'content_text': " Time to time. I also watch some high school because my friend's son plays, it would be cool if Snoop Dogg made my friend's son a theme song for his football team",
'content_type': 'text/plain',
'created_at': 1694453558,
'id': 'jzngcqyn',
'topic_id': 'lt7',
'updated_at': 1694453558,
'user_id': 'ltuser40',
'version': 0
},
},
{
'document': {
'content_text': ' You know there was a time when Marvel offered the rights to their characters to Sony but they only bought the rights for Spiderman',
'content_type': 'text/plain',
'created_at': 1694451003,
'id': '3qecs1pf',
'topic_id': 'lt95',
'updated_at': 1694451003,
'user_id': 'ltuser22',
'version': 0
},
}
],
'out_of': 188378,
'page': 1,
'request_params': {'collection_name': 'public.messages', 'per_page': 5, 'q': '*'},
'search_cutoff': False,
'search_time_ms': 35
}
Search API ¶
Now let us focus our attention to the frontend again. So far we have a search index being built as we CRUD topics, messages and users. However we do not want our client to have direct access to Typesense. This is not a safe or efficient practise:
- Typesense is an implementation detail of our application and as such we do not want these internal details to be leaked to the end users. Having a single API gives us the flexibility to change store backends (eg Elastic or Algolia etc) without leaking details to the end user.
- Without an intercpeting layer, we impose dependencies on Typesense’s security/auth models etc to restrict access to different users.
- We may not want to support every query/filter/ordering type. This helps be conscious about releasing what is a fit for features one at a time. Eg to start off with, we may only be interested in searching topics and messages by titles or content text.
Given this we will expose Search API also as part of our gRPC spec (with accompanying auto-generated grpc gateway changes).
Let us consider the user interface needs now:
- Search for topics with particular titles tolerating a bit of fuzziness - Eg we might want to search for titles ignoring stop words.
- We want to filter all the messages in a topic matching certain text (again allowing for fuzziness)
- Find all topics where messages might contain certain phrases or text.
- Search for topics with tags (we will update our Topics API for this).
This gives us a taste of what to expect from our search index store and we can add more features beyond just textual searches (eg top voted/liked topics/messages, active users etc) as we add more features.
With this we can take a stab at our Search service: